

Blog by: Greg Durrett
Work by: Jifan Chen, Yasumasa Onoe, and Xi Ye
Dec. 31, 2022
I'm wrapping up my first NSF grant (a "small" grant) as a principal investigator (Award 1814522; RI: Small: Applying discrete reasoning steps in solving natural language processing tasks). I'd like to share a retrospective on this award and what happened during the course of it.
This ended up being a 4-year award which was proposed in the fall of 2017 and which started in the fall of 2018. The proposal was written two months before ELMo came out and about 10 months prior to BERT, so in some sense it's a bit of a time capsule. I'm going to explain what we proposed, what we did, and how that connects to where we are today.
The proposal: We proposed to design latent variable models that capture discrete reasoning processes for NLP tasks, then use auxiliary "handholding" supervision during learning to constrain this reasoning and enable the models to generalize. Our approach centered on three key ideas:
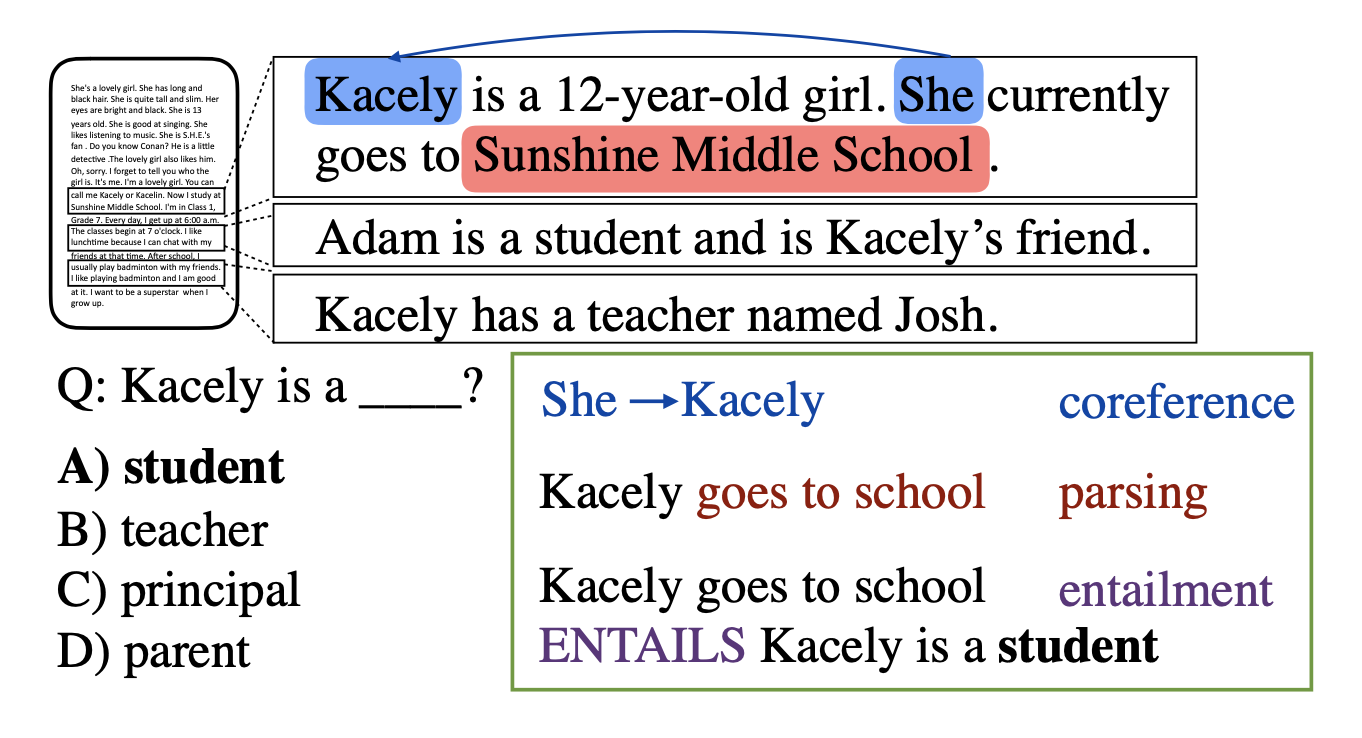 What we proposed: We proposed to explore ways of searching for discrete paths to connect the question to its answer.
Our view was that discrete reasoning could leverage intermediates like parsing and coreference to extract and repackage information from the text,
then use something like an entailment model.
Our target was the RACE dataset; however, we were quite fortunate in that WikiHop and HotpotQA, released after the proposal was submitted, provided a natural outlet to study these ideas.
What we proposed: We proposed to explore ways of searching for discrete paths to connect the question to its answer.
Our view was that discrete reasoning could leverage intermediates like parsing and coreference to extract and repackage information from the text,
then use something like an entailment model.
Our target was the RACE dataset; however, we were quite fortunate in that WikiHop and HotpotQA, released after the proposal was submitted, provided a natural outlet to study these ideas.
What we did: I think we largely delivered on the goals of this part of the proposal in the following papers.
In EMNLP 2022, we took the first step towards doing fact-checking with an approach like this, which I think ultimately combines the ideas of multi-hop reasoning and needing some discrete evidence aggregation. We are still in the preliminary stage with data collection, so we'll see where this goes!
What others did: This paper by Ben Bogin, Sanjay Subramanian, Matt Gardner, and Jonathan Berant is probably closest to what I was originally thinking. There's far too much other work to list. Peng Qi and Akari Asai both have very nice systems for graph traversal in multi-hop question answering. The rise of multi-hop question answering meant that many researchers were explicitly looking at systems with various kinds of discrete reasoning steps.
What we proposed: We proposed to extend standard OntoNotes coreference systems by incorporating two additional terms based on "paths" taken through a knowledge base. For example, the rare entity "Palau" could be linked to its Wikipedia entity, recognized as a "country", and then linked to the nominal "land" with a discrete chain of reasoning.
What we did: We ended up doing a lot of work on understanding entity knowledge but applied it more to named entity disambiguation (entity linking) rather than coreference. This is related to coreference in that it involves resolving entity identity, but the techniques are quite different because of the different cues that are relied on.
The latter two papers specifically show how to use entity typing as an intermediate reasoning step for entity linking and coreference. Although we don't have a complete reasoning chain per se, we still showed that having entity types as an intermediary was useful. I think the ideas about these entity representations are still quite relevant, even though end-to-end models built on pre-trained Transformers have clearly won out over what we were thinking in 2017.
What others did: In terms of ideas that helped coref the most, the two biggest ones are probably SpanBERT and the QA approach from Wei Wu et al. from Shannon AI. My problem with coref as a task, and one reason that we haven't worked on it more, has always been the boundaries of the relations: lots of coref is fairly trivial, then there are lots of interesting other relations like bridging that it doesn't capture, so the amount of hard and useful information that coref systems give is limited. The recent Text-based NP Enrichment work by Yanai Elazar et al. addresses this somewhat.
What we proposed: What we wanted to do a was a better-structured take on the approach of Wang Ling et al. in their very nice program induction paper. We felt that their rationales were too tied to noisy and ambiguous language and instead could be anchored more strongly in a few steps of a computational process. This just needed the right search over latent derivations and the right supervision of such derivations.
What we did: Not much on math word problems directly. We spent about 8 months looking at this and didn't make much progress. Part of the reason is that the AQuA dataset was really too challenging for methods in 2017-2018. However, we had a parallel line of work on program synthesis from natural language and examples (see Xi Ye's blog post on the topic summarizing our work there), which delivered on some of the same ideas.
What others did: Collected better datasets: Aida Amini et al.'s MathQA dataset and others like GSM8k are a lot more tractable than the AQuA dataset, which is still very challenging even for modern methods. We've seen that pre-trained Transformers have really shined here recently with the chain-of-thought work on GSM8k and Minerva.
I do still firmly believe in the ideas of this proposal and I think the core directions are still very relevant in 2023. Having intermediate reasoning processes is great for supervising models and producing inherently explainable and debuggable answers. The biggest thing we did not predict was that we would be doing this with natural language, as opposed to structures like paths over coreference chains. Back in 2017, we certainly had no idea that pre-trained Transformers would become so adept at following natural language instructions.
The other thing that's become clear is that many of these tasks are too "natural language-y" and not "formal logic-y" enough for intermediate structure to really help. For a dataset like DROP, there's a clear computation layer separate from the language understanding, and most of the approaches to this dataset recognize and use that. However, the much looser computation across relations like coreference and dependencies has a very different form. These structures do not support rule-based processing; you still end up needing to feed them into a modeling layer (like a pre-trained Transformer) to use them. Ultimately, NLP researchers discovered that pre-trained models are better at language-in-language-out than reckoning with intermediate structure, so then the value of having this intermediate structure almost vanishes.
Finally, there is a lot of evidence that BERT already learns many of the dependency and coref relations needed here (see Tenney et al., Clark et al.). I think the core idea of this proposal, that these annotations are needed as a vehicle for computation, is not as true given scaling. However, these representations can still be useful as vehicles for annotation or representation (see Tanya Goyal's dependency arc entailment work, which labels dependencies as factual/non-factual in the context of automatic summaries).
I am deeply grateful to the NSF for funding this proposal during my first year as a PI. I definitely got extremely lucky (believe me, I have no shortage of rejected proposals since then) and this really helped kick-start the initial directions of my lab.