

Blog by: Xi Ye
Work by: Xi Ye, Qiaochu Chen, Xinyu Wang, Isil Dillig, Greg Durrett
Oct. 23, 2021
Specifying a problem in natural language and then generating code to solve it is an exciting goal. But this type of code generation is hard to scale beyond short snippets: natural language is inherently ambiguous and does not provide a strong enough constraint on a program’s semantics for complex computation.
How can we enable users to construct longer, more complex programs? This blog post summarizes our research on synthesizing programs from both natural language and examples, which we have benchmarked in the domain of regular expressions.
Significant prior work has explored systems that can synthesize programs from natural language or from given I/O examples, using each type of input in isolation.

The programs generated by these approaches are typically very simple (syntactically and functionally). But is this useful in practice? Here’s the kind of problem that a programmer might actually have when they post on Stack Overflow:
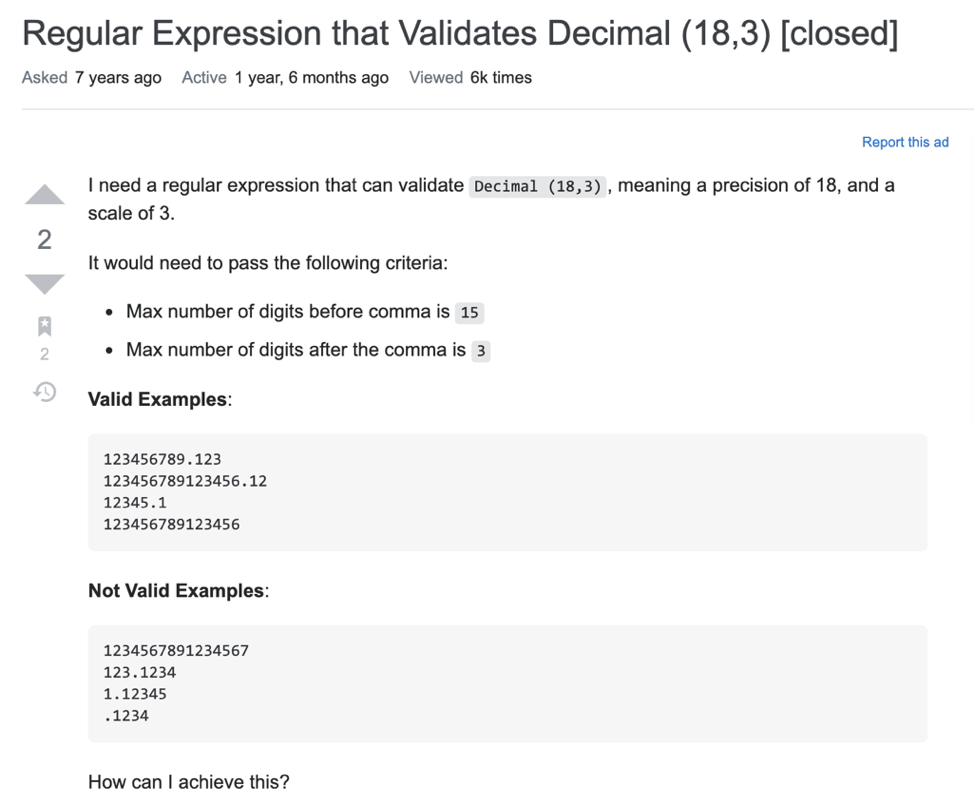
In this post, the user wants to write down a regex for validating certain decimal numbers. Notice that in this example, the user doesn’t just describe what they want -- this is too underspecified. Instead, they also provide some input-output examples. The key to scaling up program synthesis is to leverage multimodal inputs: natural language together with I/O examples.
Let’s take a closer look at this description. This description is actually underspecified. It fails to specify the acceptability of certain corner cases, e.g., is it okay if there are no digits in the integer part, like .12345?

Fortunately, the user supplemented the NL with the following positive/negative examples the regex should/shouldn’t match.

Now the underspecification is resolved, and we can figure out the answer to this post, as:

Here, NL and examples work together to fully define a program. This is a common way in which users convey their intent. For a complex program, it is generally impractical to write down a comprehensive description that covers every corner case and every detail, or provide a small and neat set of I/O examples that clearly describe the whole functionality.
Our research presents two new regex synthesis datasets, a small-scale real-world one and a large-scale one inspired by the real data, as well as two new approaches combining NLP models with PL techniques.
As the name suggests, we collect the StackOverflow dataset from the posts on StackOverflow. It is a real-world dataset consisting of 62 user-written NL descriptions organically paired with positive/negative examples.
Compared to prior synthetic datasets, KB13 (Kushman and Barzilay, 2013) and NL-Turk (Lacasio et al., 2016), the NL descriptions of StackOverflow are much more diverse and the programs are much more complex. This is starkly demonstrated by the fact that a seq-to-seq model trained on NL-Turk cannot solve any of the examples in the StackOverflow dataset (0% accuracy)! We show an typical example of each of the datasets below.

The StackOverflow dataset is limited in size, due to limited resources and the human effort required in the process. To enable the development of large-scale neural models in this more realistic regex setting, we collect a new dataset, named StructuredRegex, for benchmarking multimodal regex synthesis with complex structures.
As shown in the figure below, we adopt a new methodology for data collection to construct deeper programs. We first use a controlled grammar to generate complex regexes following three high-level templates inspired by real-world regex use-cases. Then, we augment each regex with a set of positive and negative examples, as well as a visual figure abstracting the function of the regex. Finally, we present crowdsourcing workers with the figure and examples and ask them to describe the pattern. Despite not necessarily being familiar with regexes, we found crowdworkers were able to do this task with high reliability.
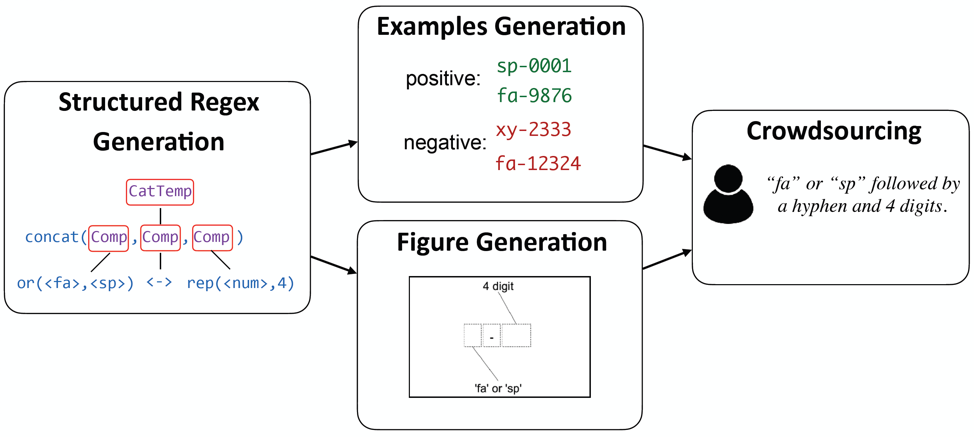
Moreover, by showing a graphical representation, we can elicit lexically diverse data by not biasing crowdworkers to a particular way of describing things, leading to linguistically complex examples:

To address the challenges in these datasets, new techniques are needed. For the multimodal setting, how do we efficiently synthesize programs with a combination of hard constraints (I/O examples) and soft constraints (NL description) from distinct sources?
We present two approaches to this problem. The first is a data-poor approach that we designed for the StackOverflow setting assuming limited or no in-domain training data. The second is a data-rich approach that leverages our large StructuredRegex dataset. Together, we believe these approaches help illustrate a family of techniques for this kind of multimodal program synthesis -- the same concepts are compatible with pre-trained modeling frameworks and other advances that have been taking place.
We first explored a sketch-driven framework that combines an NLP model and a program synthesizer by introducing a sketch as the intermediate representation. A sketch is an incomplete program with holes to denote uncertain components or constructions.

As shown in the figure above, We first map the NL into a sketch using a semantic parser. The sketch can be interpreted as a concatenation of two parts, where the first part consists of some digits and a decimal, and the second part is the combination of decimal and 1 - 3 digits. The sketch here coarsely captures the basic meaning of the NL and defines a skeleton of the target program, but accommodates the under-specification and ambiguity in NL.
Then we take the sketch and the I/O examples to derive a complete regex using a program synthesizer. The program synthesizer runs a top-down enumerative search over the program space until we find a complete regex that satisfies the I/O examples. The program synthesizer can search efficiently by pruning search states using existing techniques from program synthesis.
The semantic parser can be either a neural parser or a grammar-based parser. For StackOverflow, we use a grammar-based parser to inject expert knowledge into the framework. Our framework is able to solve 56% of the posts in StackOverflow dataset, whereas other approaches utterly fail. More importantly, this is achieved with only weak supervision: we don’t require any annotated sketches to train our framework.
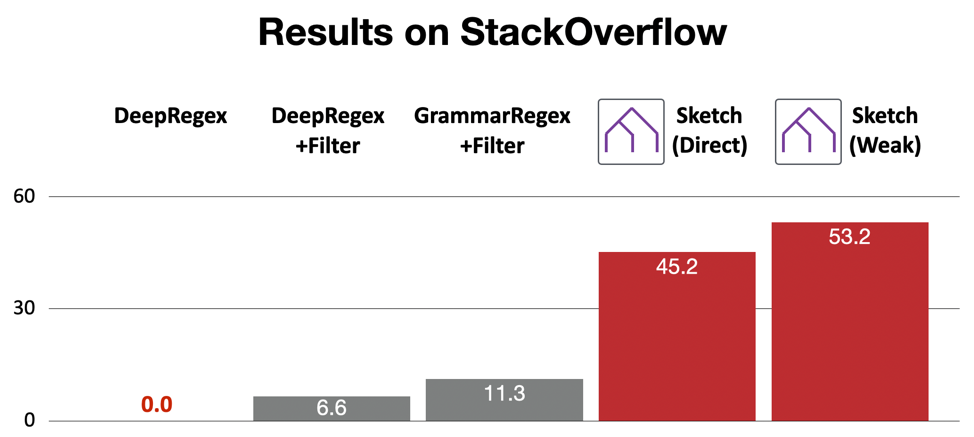
In our sketch-driven framework, the neural model produces a sketch rather than the final program. While this modularity lets us adapt to a low-data setting, it’s natural to ask whether more data can allow our synthesizer to prioritize programs in a learned way.
We first cast the multimodal synthesis task as optimal synthesis: finding the optimal program that satisfies the hard constraint while also maximizing the program's score with respect to a neural model. There could be many programs satisfying the I/O examples, but our assumption here is that the one with the highest score under the neural model is likely the best match for the NL description, and is more likely to be the user-intended program. Optimality here does not guarantee to return the correct program, only the best program under the model -- but this is still a nice guarantee to have, and it’s the best we can do given imperfect signals from the user.
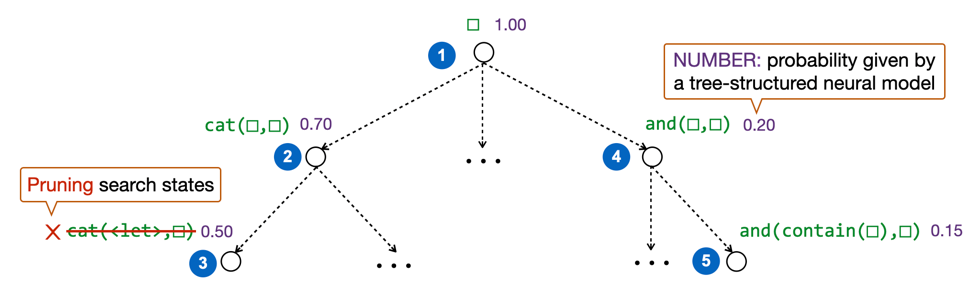
We propose an optimal synthesis algorithm to find the optimal program. We integrate a top-down synthesizer with a tree-structured neural model. The neural model places a probability distribution over the entire program space including incomplete partial programs conditioned on the NL. The synthesizer enumerates the programs best-first, strictly following the descending order of the scores directly taken from the neural model. Therefore, the first I/O-consistent program must be the optimal one. Compared to the sketch-driven framework, the optimal synthesis approach is purely data-driven, so it is likely to work better when there is sufficient training data.
We experiment with our optimal synthesis algorithm on the StructuredRegex dataset. Our optimal synthesis approach solves substantially more problems (accuracy) with significant speed-up (efficiency). In addition, our approach also finds substantially more optimal programs compared to other techniques.
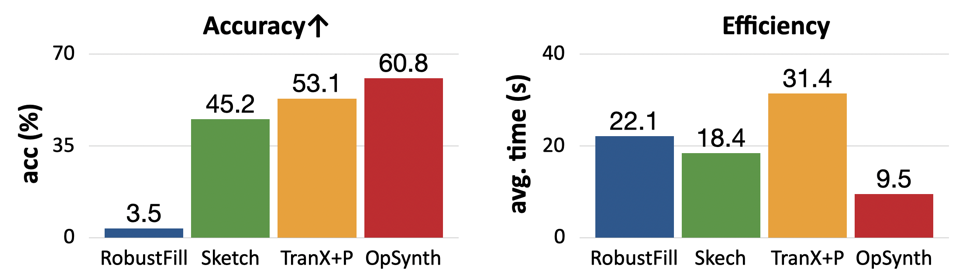
Overall, this line of work has explored the question of how to scale program synthesis (and specifically regex synthesis) to more realistic settings. Our datasets highlight the complexity of real-world problems, showing that it's hard to fully specify a real-world program with either NL or I/O examples alone. We show combining NLP models and program synthesizers can effectively handle the multimodal information from distinct sources which allows generating complex real-world programs.
We have shown the power of combining NLP models with program synthesizers. But in our approaches, the NLP models still pretty much function on their own, just giving scores to programs independent of those programs’ behavior. One potential avenue for improvement is to learn from the execution results provided by the synthesizer: when we find a partial program is inconsistent with the I/O examples, can we identify which part of the partial program is bad and tune the scores appropriately?
Another clear next step is an interactive setting. Eliciting examples is a natural way to deal with underspecified edge cases. If our system could identify these edge cases and ask the user questions, it could enable a more natural feedback loop. This could consist of asking for more examples, asking if a certain example is acceptable, or even asking for clarification on the description. These are challenging next steps, but crucial ones for helping users build correct programs in these complex settings!